
マルチモーダルAIモデルの王者OpenAIは、日々進化を続けています。基本的なGPT-3.5から始まり、GPT-4 Turbo、Whisper、Sora、GPT-3.5 Turboと、ChatGPTは長い道のりを歩んできました。新しくリリースされたGPT-4oというAIモデルは、リアルタイムでユーザーと会話し、見て、対話することができます。それは、以前のChatGPTバージョンよりも、視覚機能を備えた最先端のモデルです。
GPT-4oとは?
OpenAIの新しいフラッグシップモデルであるGPT-4oは、音声、視覚、テキストをリアルタイムで推論することができます。GPT-4o(”o “はOmniの意味)は、GPT-4レベルのインテリジェンスを提供する人間とコンピュータのインタラクションを保持します。平均320ミリ秒、232ミリ秒の音声入力に応答することができる。GPT-4oは、ユーザーによって共有された画像を理解し、議論することに優れている。ユーザーは画像を取り込み、GPT-4と会話し、画像について学びながら翻訳し、推奨を得ることができる。OpenAIは、Plusユーザーが早期にアクセスできるアルファ版で、高度な機能を備えた新しい音声モードを開始する予定です。
ChatGPTは現在、サインアップ、ログイン、ユーザー設定などで50以上の言語をサポートしています。GPT-4oの言語機能は、品質とスピードが向上しています。このモデルはChatGPT PlusとTeamユーザーに展開され、Enterpriseユーザーは近日中に利用可能になります。無料ユーザーも一定の利用制限でアクセスできます。制限に達すると、ChatGPTは自動的にGPT-3.5に切り替わり、ユーザーは会話を続けることができます。ChatGPTプラスユーザーは無料ユーザーの5倍のメッセージ制限があり、チームとエンタープライズユーザーはさらに高い制限があります。GPT-4oはAPIが大幅に改善され、より速く、50%安くなりました。
毎週、1億人以上の人々がChatGPTを利用しています。このため、OpenAIは先進的なAIツールをできるだけ多くの人が利用できるようにすることを目指しています。GPT-4oを利用することで、ChatGPT無料ユーザーは以下の機能を利用することができます:
- GPT-4レベルのインテリジェンスを体験できます。
- モデルとウェブの両方から回答を得る。
- データを分析し、グラフを作成する。
- 撮影した写真についてチャット。
- ファイルをアップロードして、要約、執筆、分析をサポート。
- GPTとGPTストアの発見と使用
- メモリーでより役立つ体験を構築
GPT-4oの新機能?
新モデルGPT-4oは、オールインワンモデルのアプローチを採用し、従来モデルのいくつかの制限を克服しています。このモデルは、GPT-4 TurboやWhisper-v3のようなモデルを上回る、強化された音声対話機能を備えています。
質の高い応答
Whisper、GPT-4 Turbo、TTSをパイプラインで組み合わせた以前のOpenAIシステムでは、推論エンジン(GPT-4)は、トーン、背景雑音、複数の話者のダイナミクスを無視して、話し言葉のみを処理することができました。この制限により、GPT-4ターボは、様々な感情や話し方で応答を行うことができませんでした。
テキストと音声の両方について推論できる単一のモデルを統合することで、この豊富な聴覚情報が応答品質を向上させ、より幅広い発話スタイルを可能にします。
低遅延でのリアルタイム会話
従来の3つのモデルによるパイプラインでは、ChatGPTに話しかけてから応答を受け取るまでにわずかな遅延(「レイテンシ」)が生じていました。OpenAIの報告によると、Voiceモードの平均待ち時間はGPT-3.5で2.8秒、GPT-4で5.4秒です。一方、GPT-4oはわずか0.32秒という驚異的な平均待ち時間を達成しており、GPT-3.5の9倍、GPT-4の17倍も高速です。
人間の平均応答時間0.21秒に近いこの待ち時間の短縮は、頻繁なやり取りが発生し、応答ギャップが蓄積する会話型ユースケースにとって極めて重要です。この改善は、グーグルが2010年に開始したインスタント(Instant)を彷彿とさせる。インスタントは、検索クエリを自動補完して、ユーザーが使用するたびに数秒を節約し、製品体験全体を向上させる。
GPT-4oの待ち時間の短縮によって可能になる注目すべきユースケースの1つは、リアルタイムの音声翻訳である。OpenAIは、2人の同僚(1人は英語、もう1人はスペイン語)がGPT-4oを使ってリアルタイムで会話をシームレスに翻訳するデモを行いました。
GPT-4oの統合ビジョン機能
GPT-4oの高度な統合機能には、画像やビデオ処理も含まれており、音声やテキスト以外の機能も強化されています。GPT-4oは、コンピュータ画面にアクセスすることで、画面上のコンテンツを説明したり、画像に関する質問に答えたり、さまざまなタスクの副操縦士として支援することができます。スマートフォンなどのカメラに接続すると、GPT-4oは周囲の状況をリアルタイムで説明できる。
OpenAIは、GPT-4oが動作する2台のスマートフォンで会話を行う包括的なデモを披露した。1台のGPTがスマートフォンのカメラにアクセスし、視覚的なアクセスを持たないもう1台のGPTに映像を説明した。このセットアップにより、人間と2人のAIによる3者間会話が実現した。印象的だったのは、デモの中でAIが一緒に歌うシーンがあったことだ。
この機能強化は、AI能力の大きな飛躍を意味し、実世界のシナリオにおいて、よりインタラクティブで多彩なアプリケーションを可能にする。
ChatGPTデスクトップアプリ
OpenAIはmacOS用のChatGPTデスクトップアプリを発表しました。これはGPT-4o専用ではありませんが、レイテンシーとマルチモダリティの強化を補完するものです。この新しいアプリは、特に専門的な場面でのChatGPTとのインタラクション方法を変革するものです。例えば、OpenAIは、音声コマンドを使用してコーディングワークフローを拡張するためにアプリを使用する方法を示しました。このアプリケーションやその他の使用例については、以下の使用例セクションを参照してください。
GPT-4oの性能と他のモデルとの比較
GPT-4oは、いくつかの従来のベンチマークで測定されましたGPT-4 Turboレベルのパフォーマンスを達成。このベンチマークは、テキスト、コーディング、推論に設定されており、多言語、音声、視覚の機能も強化されています。OpenAIはGPT-4oをテキスト評価、音声ASR性能、音声翻訳性能、M3Exam Zero-Shot、Vision Understanding Evalsで評価しました。
OpenAIは、GPT-4 Turbo、GPT-4(初期リリース23-03-14)、Claude 3 Opus、Gemini Pro 1.5、Gemini Ultra 1.0、Llama3 400bを含む他のハイエンドモデルと比較しながら、GPT-4oのベンチマーク数値を公開しました。
推理力の向上-GPT-4oは、0ショットのCOT MMLU(一般知識問題)で88.7%の新ハイスコアを記録しました。
音声認識の向上-GPT-4oは、すべての言語、特に低リソース言語において、Whisper-v3音声認識モデルよりも向上しました。
改善された音声翻訳-GPT-4oは、MLSベンチマークにおいてWhisper-v3を上回り、最先端の音声翻訳に新たな基準を打ち立てました。
M3Exam-このベンチマークは、図やダイアグラムを含む標準化されたテスト問題を使用して、多言語および視覚能力を評価します。GPT-4oは、問題数が限られているため、スワヒリ語とジャワ語のビジョン結果を除いて、このベンチマークですべての言語においてGPT-4を上回りました。
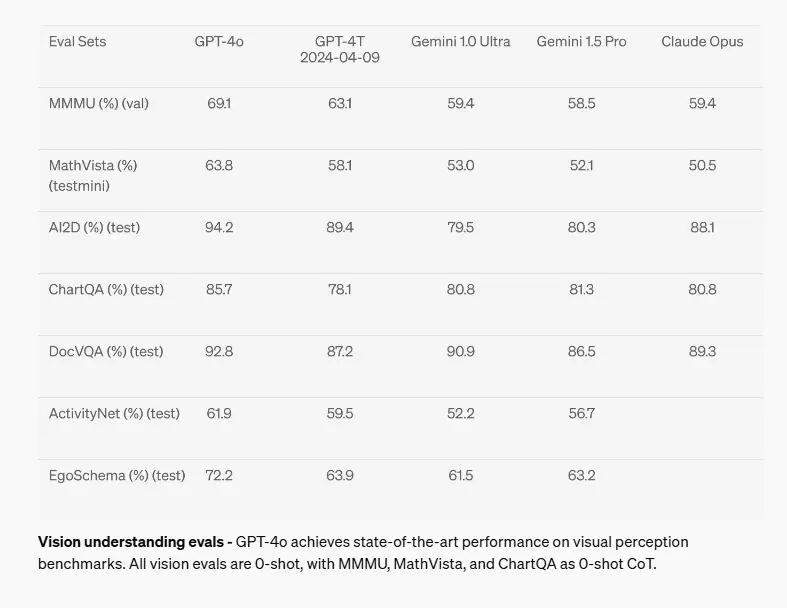
視覚理解評価- GPT-4oは視覚認識ベンチマークで最先端の性能を達成。すべての視覚評価は、MMMU、MathVista、ChartQAを含むゼロショット学習とゼロショット連鎖思考(CoT)で実施されています。
GPT-4o API: 価格と使用例
マルチモーダルモデルGPT-4oは、テキスト、オーディオ、ビジュアルデータを処理・生成します。従来のテキストのみのモデルとは異なり、より自然で直感的なユーザーとのインタラクションを実現します。GPT-4oは、GPT-4ターボよりも応答速度が速く、より優れたオーディオとビジュアル機能を備えています。既存のテキストのみのモデルより強力で、GPT-4 Turboより50%安価です。
開発者は以下の手順でOpenAI APIを通じてGPT-4oを使用することができます:
APIキーを生成する
OpenAI APIウェブサイトからOpenAIアカウントにサインアップします。
APIキーのページに移動し、新しいAPIキーを生成します。必要に応じて新しいものを生成することができますが、二度と見ることができないので、安全に保存することを忘れないでください。
Python環境をセットアップする
コマンドプロンプトかターミナルでインストールコマンドを実行して、OpenAIのPythonライブラリをインストールします。
必要なOpenAIモジュールをPythonスクリプトにインポートします。
APIコールを行う
your_api_key_here “を実際のAPIキーに置き換えて、APIキーでPythonスクリプトを認証します。
クライアント接続を利用して、テキスト生成のためにGPT-4oへのリクエストを開始します。
GPT-4o API: 音声とビデオの使用例
音声の文字起こしや要約は、アクセシビリティの向上や生産性の向上など、様々な分野で重要性が増しています。GPT-4o APIはテキストデータの処理と理解に優れていますが、現在のところ、文字起こしのようなタスクのための直接音声入力はサポートしていません。しかし、開発者はGPT-4oを活用してテキスト分析や要約を行う前に、他のツールを使って音声をテキストに変換することができます。
ビジュアル・データ分析もまた、ヘルスケアからセキュリティまで幅広い分野で重要な役割を果たしている。GPT-4oのAPIは、詳細な画像解析を可能にし、ビジュアルコンテンツに関する議論を促進し、画像から重要な情報を抽出します。この機能により、アプリケーションはビジュアルデータをシームレスに解釈し、相互作用することができます。
OpenAI API価格
OpenAIは、GPT-4o APIをGPT-4 Turboの半分の価格で提供し、以前のモデルよりも手頃で効率的なものにしました。価格設定は、入力が500万トークンあたり500ドル、出力が1500万トークンあたり1500ドルで、ビジョン機能の価格は150x150pxの画像あたり0.001725ドルです。この競争力のある価格設定により、GPT-4oはClaudeやGeminiのような他の高度な言語モデルと比較して、費用対効果の高い選択肢となっている。
さらにコストを削減するために、ユーザーはバッチ処理を利用し、プロンプトを最適化することで、APIの呼び出しとトークンの使用を最小限に抑えることができます。パフォーマンスを向上させるには、キャッシュや非同期プログラミングを実装することで、待ち時間の問題を軽減することができる。
GPT-4oは幅広い機能を誇るが、特定のニーズに合致しているかどうかを評価し、特定のタスクのための代替案や微調整を検討することが不可欠である。
言語トークン化
OpenAIは、様々な言語ファミリーにまたがる新しいトークナイザーの圧縮の表現として、20の言語を選択しました。以前のモデルと比較して、いくつかの言語ではトークンの数が少なくなっています。例えば、グジャラティ語は4.4倍少ないトークンを使用し、145から33へ、テルグ語は159から45へ、タミル語は116から35へ、マラーティー語は96から33へ、ヒンディー語は82から33へ、などです。

GPT-4oの使用例
OpenAIの継続的な成長により、モデル機能が拡張されました。GPT-4のリリースにより、オブジェクト検出、画像の分類、タグ付けが非常に簡単になりました。強化されたビジョン機能により、GPT-4をコンピュータビジョンパイプラインの他のモデルと組み合わせることが可能になり、GPT-4でオープンソースモデルを補強する機会が生まれました。

GPT-4oのリリースは、以前のモデルでは不可能だったユースケースを切り開きます。これらのユースケースはいずれも、ベンチマークのモデル性能向上とは関係ありません。
データ解析とコーディングタスク
GPTモデルとその派生モデル(GitHub Copilot)は、コード記述やバグ修正を含むコーディング支援を提供することができます。GPT-4oのマルチモーダル機能は、開発者に興味深い機会を与えます。OpenAIの研究者はプロモーションビデオで、GPT-4oを使ってPythonコードと連携するデモを行った。コードがテキストとしてGPT-4oと共有されると、GPT-4oは音声対話機能を使ってコードを説明します。その後、コードを実行すると、GPT-4oの視覚機能がプロットを説明する。プロットを画像ファイルとしてChatGPTにアップロードしてから質問を入力するよりも、ChatGPTに画面を見せて質問を話す方が簡単です。
ロールプレイ
ChatGPTはシナリオのロールプレイに最適なツールです。もしユーザーが就職面接の準備をしたり、製品をより良く売り込みたいのであれば、これは理想的なツールです。これまでのGPTはテキストのみのタスクに重点を置いていたため、GPT-4oはこの点にも改良を加えました。テキストのみのロールプレイは、すべてのユースケースに理想的ではありません。そのため、GPT-4oの改良された音声機能により、音声ロールプレイはユーザーにとって実行可能な選択肢となります。
リアルタイム翻訳
GPT-4oの翻訳機能を使えば、休暇中のコミュニケーションも可能です。携帯電話のローミング・データがあっても、GPT-4oを使えばリアルタイム翻訳が可能です。これはGPT-4oの低遅延スピーチ機能で可能です。
視覚障害者の支援
GPT-4oは、カメラからの映像入力を理解し、口頭で情景を説明することができます。この機能は、音と触覚のみに頼る視覚障害者を支援することができます。基本的には、テレビが持っている音声説明機能を実生活に応用したものです。
制限とリスク
EUのAI法は、ジェネレーティブAIを規制する唯一の法的枠組みである。これはまだ初期段階であり、AI企業は何が安全なAIを構成するかについて独自の判断を下す必要がある。OpenAIは、「低」、「中」、「高」、「クリティカル」の4段階に分類された4つの懸念領域からなる準備態勢の枠組みを持っている。このフレームワークは、モデルが一般に公開するのに適しているかどうかを判断するのに役立つ。懸念される領域は、サイバーセキュリティ、BCRNは、AIモデルが生物学的、化学的、または核の脅威を作り出す際に専門家を支援できるかどうか、説得力、モデルの自律性に関連している。
このモデルのスコアは、4つのカテゴリーにわたる評点の中で最も高い。OpenAIは、人類の文明を根底から覆すようなことに対応する重大な懸念のモデルはリリースしないと主張している。しかし、GPT-4oは中程度の懸念を示している。
しかし、GPT-4oは不完全な出力を生成する可能性がある。ジェネレーティブAIのモデルは、常に意図した出力を生成するとは限らない。コンピュータ・ビジョンは完全ではないので、画像や映像の解釈は必ずしも正確ではないかもしれない。これと同様に、話し手の方言が強く、専門的な単語が使われている可能性があるため、音声の書き起こしが100%正しいとは限りません。英語以外の言語間の翻訳も、声のトーンが適切でなかったり、間違った言語を話したりすることで影響を受けるかもしれない。
GPT-4oはディープフェイク詐欺の台頭を加速させるかもしれない。政治家や有名人、あるいは友人や家族になりすまして詐欺電話をかけることができる。GPT-4oはDeepfake詐欺の電話をさらに説得力のあるものにする力があるため、この問題は悪化する前に解決する必要がある。詐欺師はGPT-4oを使ってテキスト出力を生成し、音声合成モデルを使うことができる。しかし、それでGPT-4が与える遅延や声のトーンが得られるかどうかは不明だ。
音声出力はプリセットされたボイスの選択でしか利用できないので、このリスクは軽減できる。
結論
GPT-4oは、テキスト、音声、視覚処理を1つのモデルに統合し、視覚障害者のアクセシビリティを向上させながら、リアルタイム翻訳やデータ分析のようなアプリケーションを強化する。Deepfakeの悪用の可能性などの課題はあるものの、GPT-4oはAGIに我々を近づけてくれる。GPT-4oがより利用しやすくなるにつれて、その費用対効果と強化された機能により、日常的かつ専門的な文脈でのAIインタラクションが改善されるでしょう。今こそ、このテクノロジーについて学ぶ絶好の機会である。
よくある質問
GPT-4oは無料ですか、有料ですか?
GPT-4oはChatGPTのFree、Plus、Teamの各階層に統合され、すべてのユーザーに追加費用なしで強化されたテキストとビジョンの機能を提供します。この統合により、高度なAI機能がより利用しやすくなり、AI技術を民主化するというOpenAIの目標をサポートします。
GPT-4oはGPT-4より優れていますか?
GPT-4oは、英語テキストとコーディングのパフォーマンスにおいてChatGPT-4 Turboに匹敵し、英語以外の言語では顕著な改善が見られます。GPT-4oはGPT-4よりも大幅に高速で、既存のモデルと比較して視覚と音声の理解に優れています。
GPT-4o APIを使用するには?
ユーザーはOpenAIからチャット補完APIにアクセスし、GPT-4oモデルにアクセスすることができます。これにより、後方互換性があり、使いやすくなりました。
GPT-4o APIを利用するためのコストと、他のモデルとの比較は?
GPT-4o APIは、トークンの使用量に応じて課金される従量課金モデルを採用しており、GPT-4などの従来モデルと比較して50%の大幅なコスト削減を実現しています。他のモデルとの詳細な価格比較も記事でご覧いただけます。